LiDAR Prompted Spatio-Temporal Multi-View Stereo for Autonomous Driving
Mar 5, 2026·,,,,,, ·
0 min read
·
0 min read
Qihao Sun
Jiarun Liu
Ziqian Ni
Jianyun Xu
Tao Xie
Lijun Zhao
Ruifeng Li
Sheng Yang
Abstract
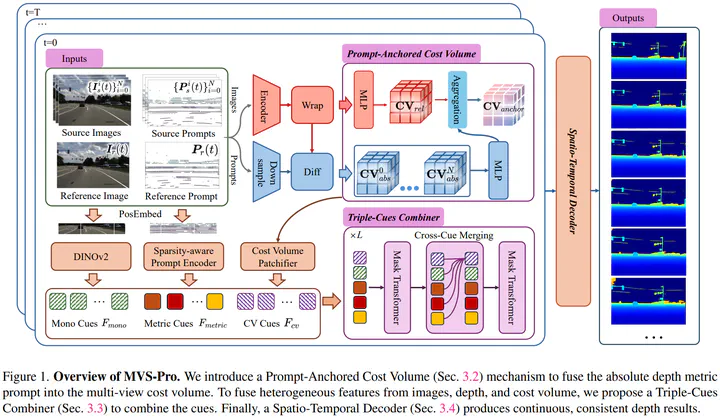
Accurate metric depth is critical for autonomous driving perception and simulation, yet current approaches struggle to achieve high metric accuracy, multi-view and temporal consistency, and cross-domain generalization. To address these challenges, we present DriveMVS, a novel multi-view stereo framework that reconciles these competing objectives through two key insights. (1) Sparse but metrically accurate LiDAR observations can serve as geometric prompts to anchor depth estimation in absolute scale, and (2) deep fusion of diverse cues is essential for resolving ambiguities and enhancing robustness, while a spatio-temporal decoder ensures consistency across frames. Built upon these principles, DriveMVS embeds the LiDAR prompt in two ways, as a hard geometric prior that anchors the cost volume, and as soft feature-wise guidance fused by a triple-cue combiner. Regarding temporal consistency, DriveMVS employs a spatio-temporal decoder that jointly leverages geometric cues from the MVS cost volume and temporal context from neighboring frames. Experiments show that DriveMVS achieves state-of-the-art performance on multiple benchmarks, excelling in metric accuracy, temporal stability, and zero-shot cross-domain transfer, demonstrating its practical value for scalable, reliable autonomous driving systems.
Type
Publication
IEEE/CVF Conference on Computer Vision and Pattern Recognition