Language Driven Occupancy Prediction
Jul 1, 2025·,,,,,,, ,·
0 min read
,·
0 min read
Zhu Yu
Bowen Pang
Lizhe Liu
Runmin Zhang
Qiang Li
Si-Yuan Cao
Maochun Luo
Mingxia Chen
Sheng Yang
Hui-Liang Shen
Abstract
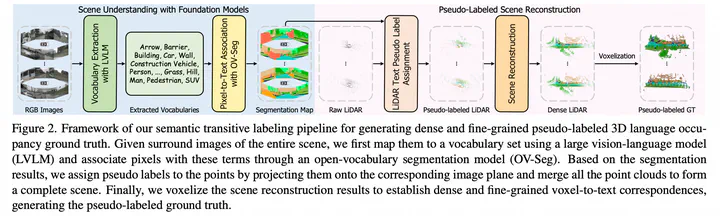
We introduce LOcc, an effective and generalizable framework for open-vocabulary occupancy (OVO) prediction. Previous approaches typically supervise the networks through coarse voxel-to-text correspondences via image features as intermediates or noisy and sparse correspondences from voxel-based model-view projections. To alleviate the inaccurate supervision, we propose a semantic transitive labeling pipeline to generate dense and finegrained 3D language occupancy ground truth. Our pipeline presents a feasible way to dig into the valuable semantic information of images, transferring text labels from images to LiDAR point clouds and ultimately to voxels, to establish precise voxel-to-text correspondences. By replacing the original prediction head of supervised occupancy models with a geometry head for binary occupancy states and a language head for language features, LOcc effectively uses the generated language ground truth to guide the learning of 3D language volume. Through extensive experiments, we demonstrate that our transitive semantic labeling pipeline can produce more accurate pseudo-labeled ground truth, diminishing labor-intensive human annotations. Additionally, we validate LOcc across various architectures, where all models consistently outperform state-of-the-art zero-shot occupancy prediction approaches on the Occ3DnuScenes dataset.
Type
Publication
IEEE/CVF International Conference on Computer Vision